![]()
 SWAG: Software
SWAG: Software
Architecture Group
Assembler clone detector
This program tries to detect potential candidate clones that arise in assembler code, typically derived from C and C++ source code. It can perform clone detection on C, C++, and assembler produced from other source languages. It only runs on platforms that generate linux gcc/g++ assembler for the intel machine language.
The supporting paper can be found here.
Download ACD
ACD is a clone detector, that discovers similarities in assembler by examining augmented lines of assembler.
The latest builds of ACD are available below. While effort has been made to test ACD, the software may contain bugs. In particular current versions of this software are likely to require test driven development, since some of the internals of this program have expectations about the format of the assembler examined which might potentially change from release to release of gcc, and g++.
Since the dwarf standard differs on 32bit .v. 64bit machines, on machines that use 64 bit pointers define the macro DWARF64 to communicate this.
| ACD 1.0.14 | [acd-1.0.13.zip] | Sun 64bit executable | ||
|---|---|---|---|---|
| ACD 1.0.13 | [acd-1.0.13.zip] | Sun 32bit executable | Sun 64bit executable | |
| ACD 1.0.12 | [acd-1.0.12.zip] | |||
| ACD 1.0.11 | [acd-1.0.11.zip] | Sun 64bit executable | ||
| ACD 1.0.9 | [acd-1.0.9.zip] | Sun 32bit executable | ||
| ACD 1.0.8 | [acd-1.0.8.zip] | Sun 32bit executable | ||
| ACD 1.0.7 | [acd-1.0.7.zip] | Sun 32bit executable | ||
| ACD 1.0.6 | [acd-1.0.6.zip] | Sun 32bit executable | ||
| ACD 1.0.5 | [acd-1.0.5.zip] | Sun 32bit executable | ||
| ACD 1.0.4 | [acd-1.0.4.zip] | Sun 32bit executable | Sun 64bit executable | |
| ACD 1.0.3 | [acd-1.0.3.zip] | Sun 32bit executable | Sun 64bit executable | |
| ACD 1.0.2 | [acd-1.0.2.zip] | Sun 32bit executable | Sun 64bit executable | |
| ACD 1.0.1 | [acd-1.0.1.zip] | Sun 32bit executable | Sun 64bit executable | |
| ACD 1.0.0 | [acd-1.0.0.zip] | Sun 32bit executable | Sun 64bit executable |
ACD is being constantly developed and improved; check back often for newer versions.
Synopsis
acd
[-a i/nstructions|l/ines]
[-b]
[-C <count>]
[-d]
[-D]
[-e]
[-f]
[-F]
[-G <clics_source_file>]
[-g <clics_assembler_file>]
[-h <directory>]
[-k]
[-l <min>]
[-L <min>]
[-M]
[-m <cost>]
[-s <cost>]
[-S]
[-r]
[-R]
[-t <output.ta>]
[-T <count>]
[-u
The -a option establishes boundaries at which clone detection may be
performed. If line boundary is specified matching of assembler clones may only
begin at the first assembler instruction associated with a line of text in the
source,
assuming that such line boundaries are known, as consequence of having
compiled the source the the -g option. Otherwise any assembler instruction
may constitute the start of a sequence of matching assembler instructions.
Line matching is the current default.
The -b option causes ACD not to find the longest possible valid clones, but
rather to truncate such clones at the point where the computed weight
associated with the clone is maximal. This will have the effect of
truncating clones prematurely, while making the clone detected potentially
seem more reasonable. However, by reducing clone length it may invalidate
some clones that would otherwise be reported.
The -d option causes the assembler associated with each function to be
printed, as it appears for clone detection purposes. This option permits
some validation of the correctness of this assembler.
The -D option causes the computed positions and sizes of variables and
arguments associated with a function to be dumped. This option permits
validation of the complex task of reverse engineering from the textual
assembler this information encodes as per the dwarf 2.0 and 3.0 standard.
The -e option permits assembler instructions derived from the same
source file and line number to be permitted to form the first pairing
in a clone pair. Distinct assembler instructions will be derived
from the same source file and line number when they are generated
by the same macro definition.
Thus this instruction indicates that trivial clones
derived as a consequence of repeated use of the same macro are to be
reported. In situations where a large macro is used to inline the
same code extensively, the
reporting of all possible pairings of such macro usage is potentially
huge, and the run time costs associated with detecting all such trivial
pairings potentially very painful. Some valid clones that begin (and perhaps
continue) with common macros with not be detected unless this option is
set.
The -f option disables references to offsets from the frame pointer
being replaced in the assembler
by the corresponding variable/argument name in the source that these
frame offsets represent (as derive from the debug information
when the assembler has been compiled using the -g option). If clone
detection is to treat variable as the same only if they occur at the
same position in the stack, rather than when having the same name, use the
-f option.
The -F option similarly disables references to temporary variable
generated by the compiler which have no corresponding source variable name
being replaced by names of the form t.0, t.1 etc. in the order
of first usage. It is presumed that the scope of such
temporary variables is limited to assembler instructions
derived from a common source statement (as established by assuming that
separate statements occur on different lines of the source).
The -G option causes acd to emit the named file with the location of clones
found in the source code, in the clics output format. Similarly, the -g
option causes acd to emit the named file with the location of the actual
clones found in the assembler. If the path contains
no '/' this path is presumed to be with respect to the html directory.
The -h option
creates html web pages under the named directory, which individually
are managable (though potentially huge in number), and linked to the
much smaller root page created with the name "index.html" in this same
directory. Absent this option no detailed output about clones is produced,
and -R and -r is implicitly implied.
The -t option generates a graph showing how clones are related that can
be directly viewed by lsedit. When used with the -h
option, edges showing how clones are related contain an html attribute
indicating the html page number generated using the -h option, that
further describes this relationship. If the filename contains no '/'
and the -h option is specified, the TA graph is placed in the directory
specified by the -h option, and linked for easy download from the main
html page.
The -T option specifies how many of the top clones are to be remembered
and reported in their own page. The default is 1024.
The weight reported (and used in the ordering)
is the sum of the lengths of the two matching clones, adjusted so as to not
count multiple lines of macros if the -M option is specified.
This report is tabular having as many
columns across the page as specified by the -C option (default 8). This
option requires the -h option, as well as not both of the -R and -r
options.
The -k option instructs acd not to delete any assembler files that it
generates. Instead they remain following execution of acd, permitting
direct examination of them. See also the -S option.
The -l option specifies the minimum number of assembler instructions that may
constitute a clone. This value currently defaults to 15. Both sides
of the comparison must involve this minimal number of assembler code
instructions
be they matching or unmatching instructions, or at least one sequence of
assembler instructions must correspond to all the instructions in a function.
The -L option specifies the minimum number of assembler instructions that may
constitute a clone when these instructions correspond to all the instructions
in a function. This value currently defaults to 14.
The -M option seeks to avoid reporting clones that result purely from
inclusion of the same macros. Clones involving multiple assembler lines
originating from the same location in the same header file, are counted
for matching purposes as a single instruction.
The -m option provides as a positive number the mismatch cost, which by
default is 1. A larger mismatch cost strongly biases the clone detection
algorithm towards avoiding declaring sequence of assembler to be clones of
each other when mismatches occur within these sequences. A very large
cost effectively insists that clones may contain no mismatches.
The -s option provides as a positive number the matching cost, which by default
is 1. A larger same cost increases the degree to which the clone detection
algorithm is forgiving of mismatches, as the number of earlier matches
seen increases.
The -S option skips the compilation of source to assembler, when the
assember is already existing. This is an efficiency option, designed
to avoid needlessly recompiling source to assembler, every time acd
is run.
The -r option indicates that the clone detection output is not to report
the corresponding lines of source code that match the assembler examined. This
option will reduce run time signicantly, since source code will not
be repeatedly scanned to find desired line that must be printed. Note that
assembler files
not produced with the debug information included within them as consequence
of having been produced by compiling with the -g option have no line
number information, and thus do not permit recovery of this source code
information.
The -R option indicates that the line by line comparison of assembler
instructions is not
required in the output. This will substantially reduce the size of the
clone detection output, at the expense of considerable loss of information.
The -u option specifies how aggressive the hill-climbing optimisation
should be in attempting to improve originally discovered clones.
If the -v option is specified then acd reports each sources file read,
upon successful completion of that processing.
In addition, any
internal compiles performed will be reported on the standard error
output.
The -z option permits correlation between the clones detected by ACD
and some other clone data hard coded by an experimenter into data.cpp.
This option is of no use to the casual user.
ACD expects to read from standard input a build history describing how
C, and C++ source code is to be built. The format and method of
capturing this history is described in the documentation for
asx.
Use of this same input history file, permits both fact extraction
and clone detection to be performed on arbitrary source code (
providing that this source can be compiled
) using the same build instructions for both programs.
The matching algorithm used by acd is based on that used by
jcd.
The software begins by reading into memory the machine instructions present
in each created/discovered assember file used in the build process. These
instructions are stored within
arrays and a certain amount of instruction manipulation is performed to
improve clone detection.
Every assembler instruction is hashed so that alternative candidate assembler
instructions that match a given instruction can be reduced to a managable
number, helping to reduce run time from O(n^2) to O(n).
Typically two assembler instructions match if they refer to the same operation
applied to the same variables. However branch instructions match if they
are the same instruction and branch in the same direction.
Starting with two distinct assembler instructions established as matching,
the clone detection algorithm examines all pairings of subsequent assembler
instructions seeking a further match. A greedy algorithm is used to
locate the next matching pair of assembler instructions. Specifically,
for incrementing numbers of skipped assembler instructions, all pairs of
assembler instructions which involve precisely this number of skipped
assembler instructions are searched for a match.
This greedy algorithm finds pairings of matched assembler instructions that
occur in the same sequence potentially interleaved with non-matched
assembler instructions. It imposes the further contraint that no
match branching instructions branch to before the start of the clone
sequence and that the instructions branched to do not lie on opposite
sides of any other matched pair of assembler instructions.
Every matched pair of assembler instructions is assigned a positive match
weight,
and every prior unmatched assembler instruction a negative mismatch weight.
The pairing of assembler instructions performed as part of clone detection
terminates when no further assembler instructions exist to be matched within
the method(s) being compared, or when the cumulative weight of all the
assembler instructions observed as part of clone detection becomes negative.
At this point the software discards from each clone the final assembler
instructions in the assembler sequence not followed by a matching assembler
instruction.
Thus if the matching and mismatch wieghts are the same value, clone detection
terminates when more mismatched assembler instructions have been seen within the
two sequences than matched ones.
This algorithm can miss long sequences of clones when false matches occur.
For example consider the sequence of assembler below:
Sequence1 will naturally match, but if sequence2 is long enough, the two
initial XYZ
entries will be matched, instead of Sequence3. Then (assuming nothing in
Sequence3 matches anything in Sequence4) Sequence4 will match.
If the argument to -u is greater than zero, then after initial detection
of matching pairs, a hill climbing algorithm is invoked to address the above
problem and so improve the result. If the result is improved, then since
the weight associated with the clone is now larger, further extension
of the clone is attempted using the basic algorithm followed by the
hill-climbing algorithm.
All ways in which instructions in the first and second clone sequence might
match are computed, with each such possible matching being considered an
edge between the two assembler instructions. Matched edges are those
derived from currently matched pairings of assembler instructions.
Then all conflicts between
distinct edges are computed. Distinct edges conflict if they share a common
end point, or if they cross. Edges derived from branch assembler instructions
conflict with other edges if the assembler pair branched to lie on opposite
sides of the other edge. When both edges derive from branch instructions
a conflict also occurs if the assembler branched by one edge to lies on the
opposite sides of the assembler branched to by the other edge.
An unmatched edge is blocked from being matched, by the number of
matched edges which conflict with it.
For each unmatched edge having at most the number of edges blocking it
specified in the -u option, in increasing number of edges blocking
such edges, a test is performed to see if unmatching all the edges
blocking this edge, permits more than the current number of matched
edges to be matched. If it does this change is applied. Upon having
examined all edges if some improvement has been achieved this algorithm
is repeated. If -I is also specified this is repeated at most the
specified number of iterations. If -E is specified with a non-zero
number of seconds, hillclimbing for any given clone pair is executed
at most this number of seconds before terminating with whatever
improvements have been made within this specified time duration.
This value currently defaults to 60 seconds.
Upon any improvement the initial
matched sequences reported to the hill-climbing algorithm can be
extended (since more matches have now occurred within it) and this
process repeated.
The hill climbing algorithm
requires considerable memory. If there are n instructions to be
compared with m instructions there are O(n * m) edges.
If there are e edges there are O(e * e) intersections of
these edges. Thus comparing 1,000 instructions against 1,000 instructions
produces O(10^12) ie O(1,000,000,000,000 crossings.
If there are more than 65,535 (ie 2^16) ways of matching individual
assemmber instructions within a clone (edges),
more than 134,217,728 (ie 2^27) conflicts between these edges, or an
inability to allocate sufficient memory to accomodate the edges and
edge crossing information the hill climbing
algorithm reports this and cleanly aborts the attempt to improve the results
presented to it.
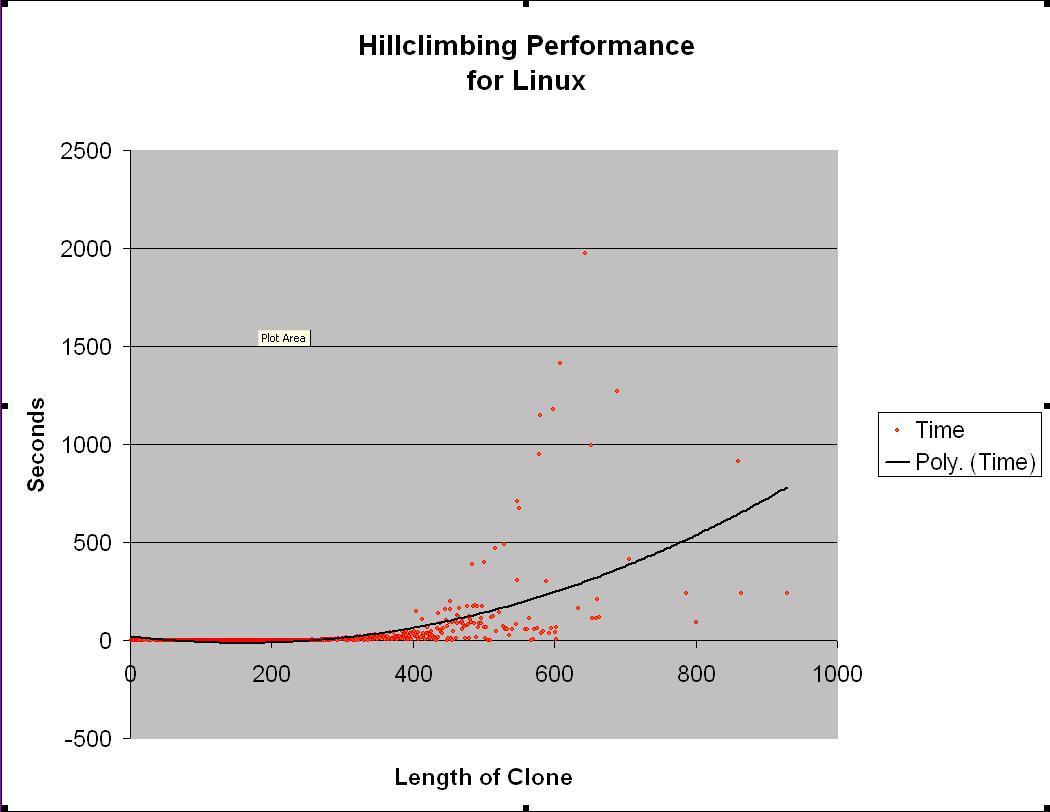
When the length of clones increase dramatically the hill climbing
algorithm can take a considerable amount of time to run. The average time
to execute the hillclimbing algorithm, allowing remove of up to 256
blocking edges, for clones obtained from linux is shown below. The
clone length is the average length of the two clones.
This program outputs html that can be viewed in any suitable web browser.
The output shows sections of assembler that are similar or the
same to other sections of assembler. If the assembler has been created
using the -g option and the -f/-F option is not employed
similarity of local variables is predicated on
their given name. Otherwise it is currently predicated on the position
of these local variables on the stack.
If the -h option is used a three tier html reporting structure is employed
with the root of this structure being in the file 'index.html' within the
indicated directory. The
top tier hyperlinks to distinct pages for each class file examined. That
page describes the clones found in this class file that match all later
assembler either in the same class file or in later class files examined.
The third tier shows for each such identified potential clone the actual
assembler, and source code that justified reporting of this clone.
Note that this option can potentially produce a huge number of small
viewable files.
Color coding is employed to draw visual attention to certain details.
Differences between code is highlighted in red on the left side, and
blue on the right. Lines derived from identical source and line
numbers (if determined to be identical) are shown with the background grayed
out, to highlight that they are effectively the same as the result of macros,
or file inclusions. Note that it is entirely possible for the same line
of source to produce different assembler, if macros within it are
themselves derived from different sources.
Note that the -r and -R options determine detail provided in the output
produced. It is recommended that neither option is used except when
disk space is at a premium, since when the -h is specified
each output page employs DHTML to permit viewing and or hiding of the
source and assembler in an interactive manner.
Graphic output suitable for viewing using lsedit
which can be hotkeyed (using lsedits command feature) back into the
html pages and/or the source code can also be produced using the -t option.
The hardest challenge in the implementation of this code was to correctly
interpret within the contents of the assembler source code, the data
structures that within the object code would convey debug information, so
as to facilitate dynamic debugging as employed for example in gdb.
It is this information which permits reverse engineering of the C and
C++ variable names, from assembler which refers to such variables as
being unnamed variables identified by offsets from the current frame
pointer. These data structures conform to the dwarf standard, which
is itself a very complex standard designed to be sufficiently powerful
to permit use under arbitrary machine architectures and across diverse
chips.
Note that the dwarf standard is a standard that defines the interpretation
of sequences of bytes in object code; and so to use this standard in
assembler source it is necessary to not only parse the
assembler source but be able to translate that source into the expected
byte sequence appearing in object code produced from this assember, and
since references are embedded within this byte
sequence to bytes in the same and other sections, to know the exact
offset of bytes referenced within the conceptual dwarf data structures
embedded within sections of the object code produced from the assembler
source examined.
For documentation on the dwarf standard see:
For documentation on name mangling see:
The version of the standard employed by an arbitrary compiler can be
determined by examining the dwarf header record, that occurs at the
start of the .debug_info section. Currently both gcc and g++ on
swag and swag-new generate dwarf according to version 2 of this
standard.
If an exception or interrupt such as generated by keyboard input of Cntl-C
is raised, this program terminates its current efforts to detect clones,
and after reporting the observed exception terminates in a fashion which
permits the results so far generated to be viewed.
rm -r /home/ijdavis/public_html/linux
Sun machines that produce from gcc and g++ assembler for intel chips
using the linux assembler conventions.
Options
Input format
Clone detection algorithm
Clone1 Clone2 Sequence1 Sequence1 Sequence3 XYZ XYZ Sequence2 XYZ Sequence3 XYZ Sequence4 Sequence4 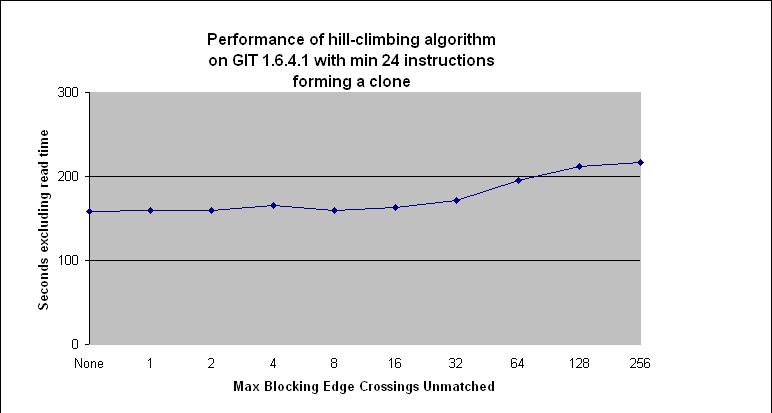
Output
Dwarf standard
Exceptions
Example output
Example usage
acd -v -k -S -M -T 2048 -t linux.ta -h /home/ijdavis/public_html/linux < history.linux
See also:
Developed by
Location
Supported platforms
Caveats
Contact information
For more information on acd please contact us at
.